Tasks
Tasks are the principal units of work in a Pipeline graph. They enable data to be read in, transformed, and written back out to connected Datastores and thereby greatly simplify data manipulation in any environment at any scale.
The Task editor can be accessed via the Pipelines page: after navigating to a specific Pipeline a tab will appear where new Tasks can be created and existing Tasks can be edited and deleted. Tasks are scoped to specific Pipelines although their core logic is defined in code files that can be shared across Pipelines.
All Tasks require name, type, and description fields and the
name field is required to be unique for Tasks of a given type within a given Pipeline.
Tasks propagate data via Aliases, which are defined in the aliases field. These aliases simply provide
a name for the tables being passed into and out of Tasks.
For example, if an upstream Task produces a table with the alias data, the downstream Task must access this table
by referencing the alias data in its code. The code will simply look for the alias to be present among any of them.
Aliases are not required to be unique across Tasks. Aliases can also reference Schemas for data validation and type enforcement.
More info about Schemas can be found in the Schemas section.
Data Readers
Data Readers are used to read data from registered Datastores using SQL queries.
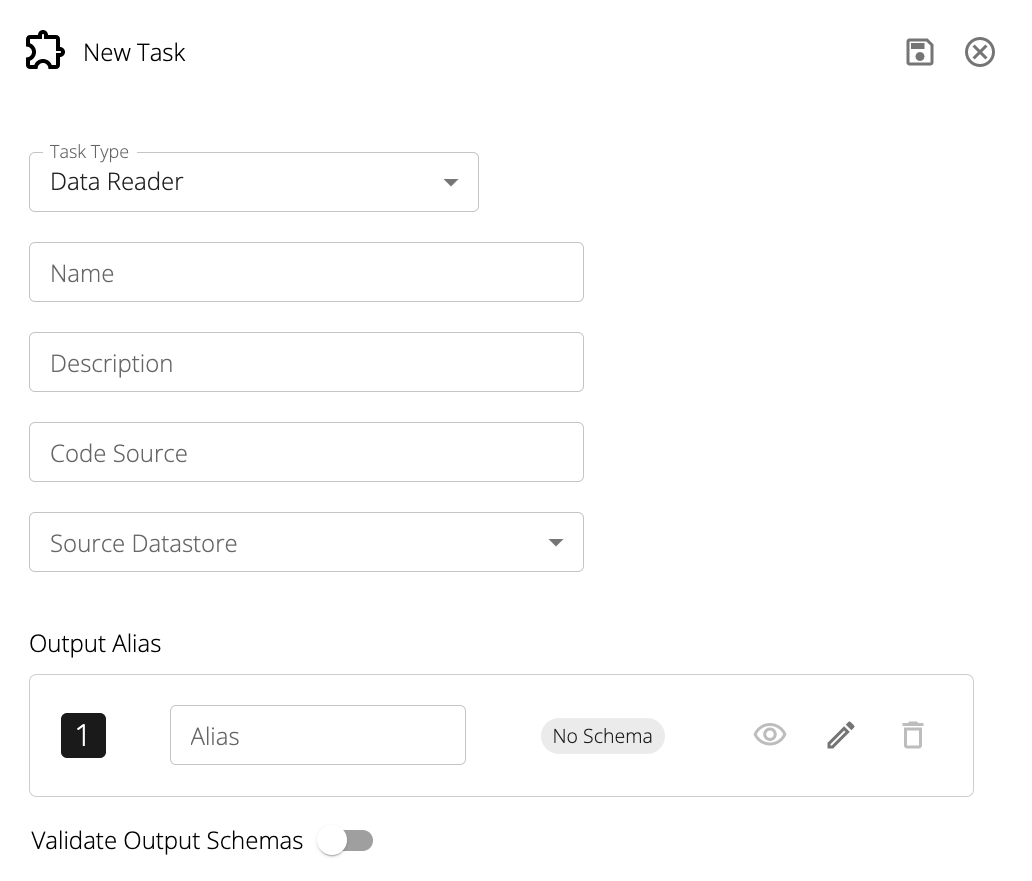
Data Readers have the following fields:
Source Datastore: The datastore to read from.
Code Source: A link to a .sql file on Git. The SQL query must be compliant with the dialect of the datastore.
The file can be on any branch in any repository so long as the connected Git integration has read access to it.
The SQL file contains the query to be run against the source Datastore in order to load in data.
| |
For S3 datastores, note that the special constant data is used to indicate the table object.
In the above example, sample.nyc_citibikes would be replaced with data if it was from S3 instead of a SQL database.
Output Alias: The name of the data produced by the query contained in the code source. Data Readers can only have one output alias.
Data Writers
Data Writers are used to write data to registered Datastores.
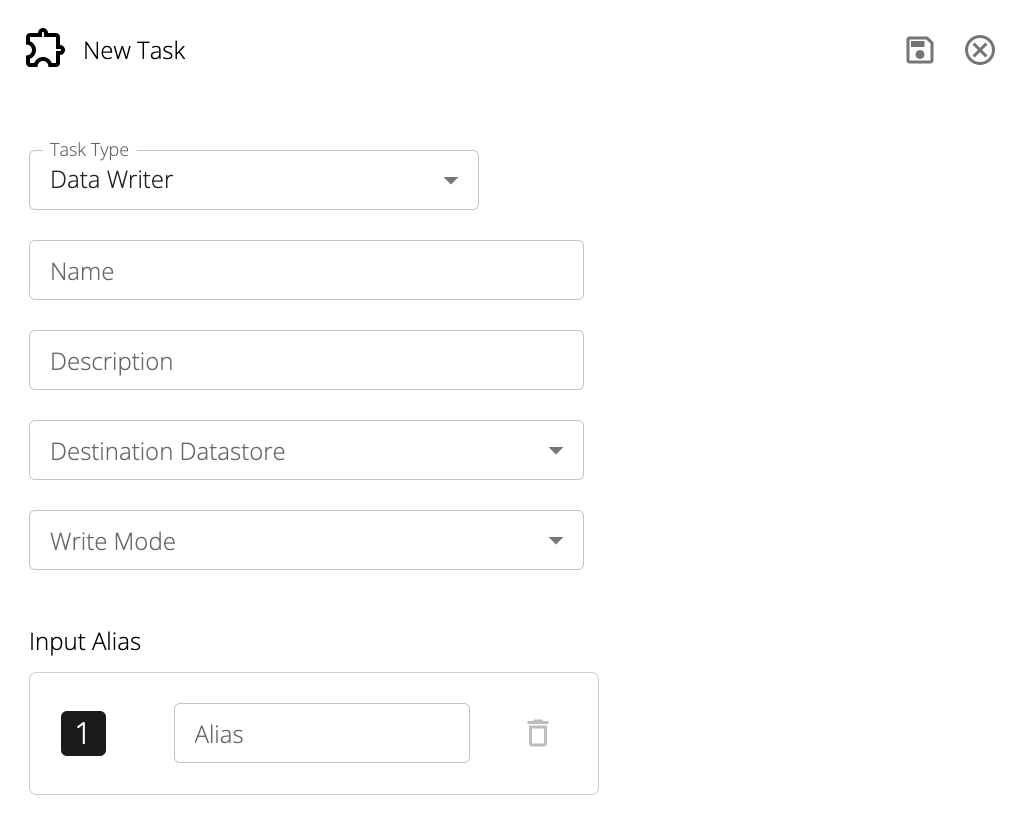
Additionally, Data Writers have the following fields:
Destination Datastore: The Datastore to write to.
Input Alias: The name of the data being written to the specified Datastore.
Write Mode: A directive specifying the write mode behavior of the task.
Data Writers can Append to, Upsert into, or Overwrite the specified table
(or for S3/GCS Datastores, the contents of the associated path).
Destination Table: The Datastore table to write to.
This field is only enabled for SQL Datastores.
It is advisable to explicitly specify the full table path (schema.table).
Warning
Note thatUpsert mode is currently experimental.SQL Transforms
SQL Transforms allow for the manipulation of data, either from outputs of other transformations or directly from Data Readers, using SQL. This source-agnostic nature of the Kaspian execution engine means that a single SQL query is capable of accessing and operating upon data from multiple Datastores and/or Pipeline branches.
Additionally, SQL Transforms have the following fields:
Code Source: A link to a .sql file on Git.
The file can be on any branch in any repository so long as the connected Git integration has read access to it.
The SQL file contains the query to be run using the aliases provided in the Input Schemas as table names.
The query must be SparkSQL-compliant. Below is an example query that utilizes the aliases above:
| |
Input Aliases: Each inbound edge to a SQL Transform represents a different data source, corresponding either to a Data Reader output or to an intermediate output of another transform Task. In order to distinguish between these inbound edges when writing the transformation query each edge must be configured with an alias and a schema.
While the same schema can be used multiple times within a SQL Transform if the data sources being read from have the same structure, aliases must be unique. An alias refers to the name that the input source table is referred to in the SQL query contained in the code source (see example below). This abstraction means that any intermediate data stage can be referred to and operated upon as if it were a materialized table even if this isn’t the case.
Output Alias: The name of the data produced by the query contained in the code source.
Python DataFrame Transforms
Python DataFrame Transforms allow for direct manipulation of data with Pandas or Pyspark. Similar to the SQL transform, this allows any number of inbound and outbound edges. This Task takes Python code source structured as follows:
| |
Due to the distributed nature of our compute engine, certain imports must be specified within the main function instead of the top of the file.
Some libraries may fail to import otherwise.
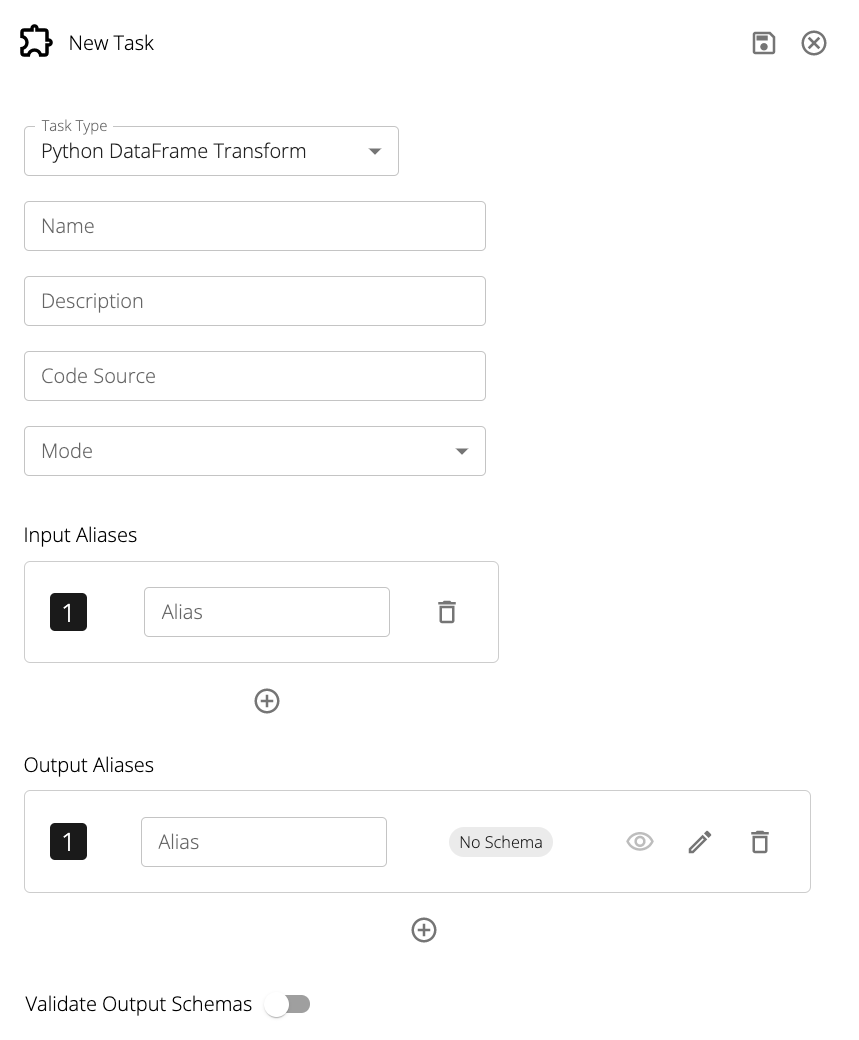
Python DataFrame Transforms have the following additional fields:
Code Source: A link to a .py file on Git.
The file can be on any branch in any repository so long as the connected Git integration has read access to it.
The Python file contains the code to be run using the aliases provided in the Input Schemas as DataFrame names.
Mode: The mode of the Python DataFrame Transform. This can be either Pandas or Pyspark.
Input Aliases: Each inbound edge to a Python DataFrame Transform represents a different data source.
For the above code example, the input aliases would be df_citibikes and df_starbucks.
Output Aliases: The name of each DataFrame produced by the Python code source.
For the above code example, there would be a single output alias: citibikes.