Schemas
Schemas define the structure of data at any point within a Pipeline graph.
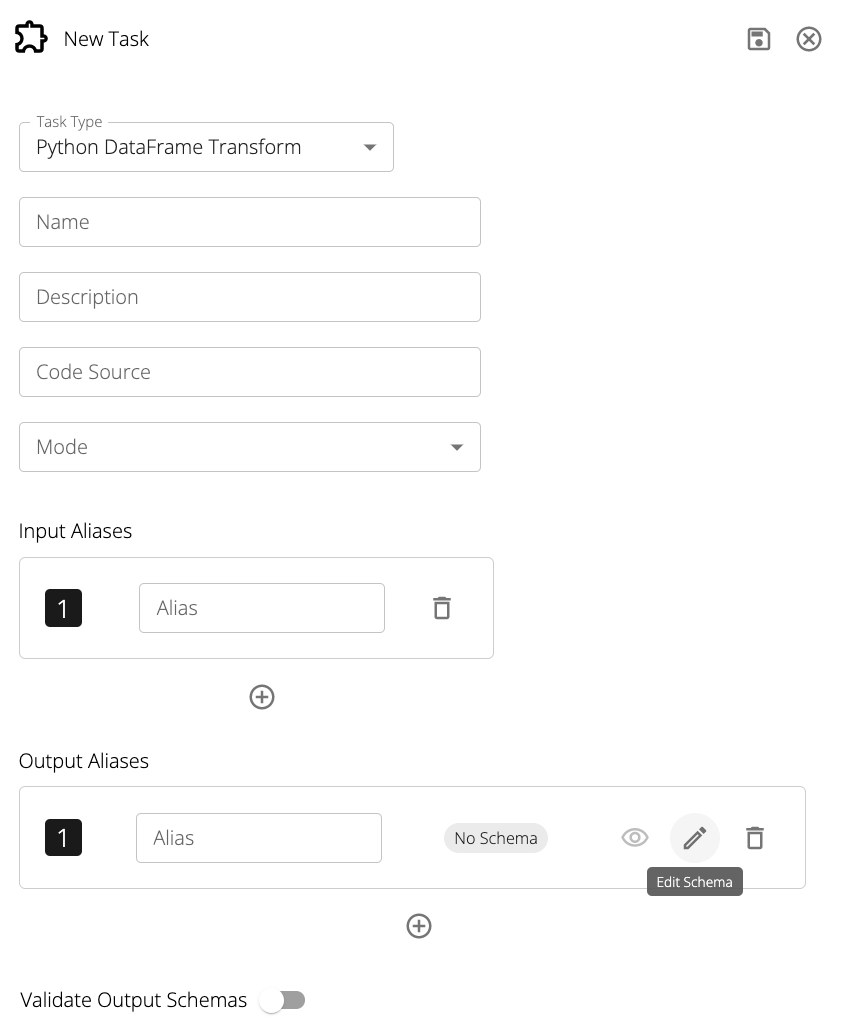
The editor also enables Schema to be edited and deleted. Schemas cannot be deleted until all Tasks, Pipelines, and Datastores that use them are also deleted and Kaspian will present the user with the relevant dependency conflict chain if a delete operation is requested.
Clicking on the Edit Schema icon will open the following modal:
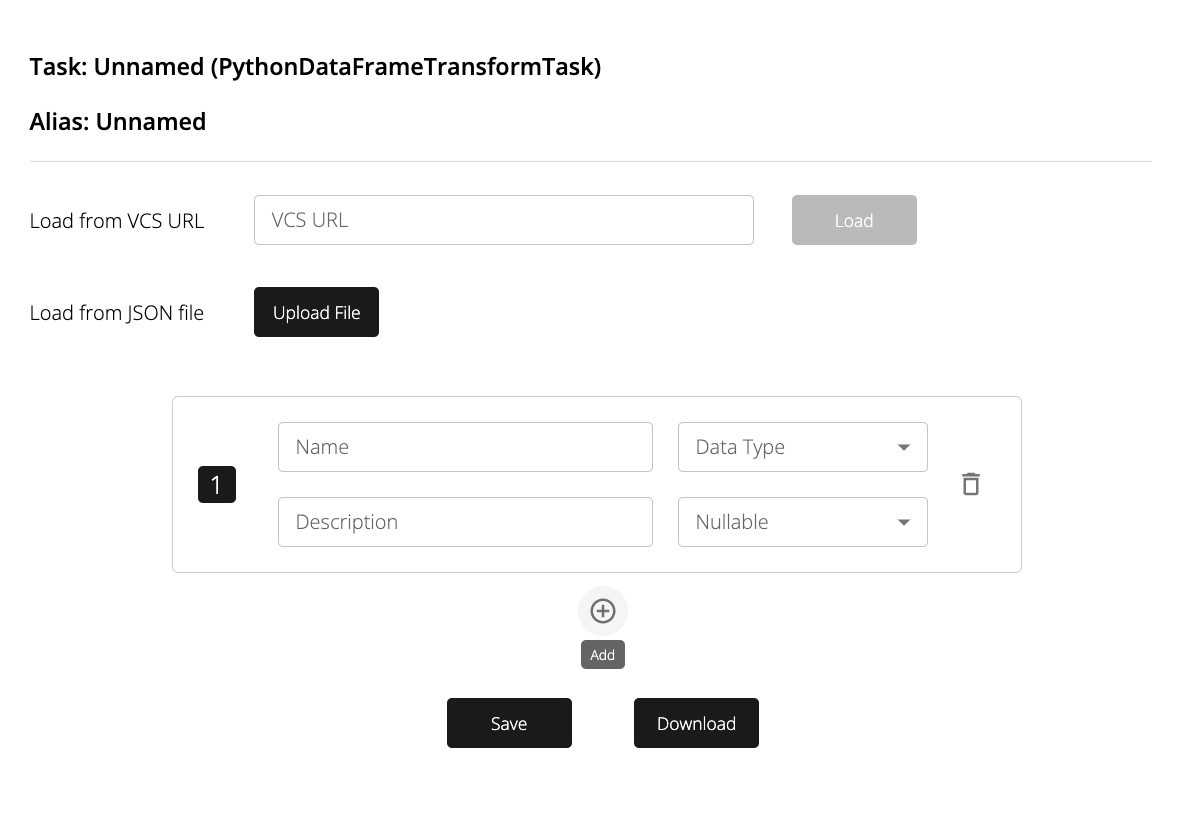
Schemas can be generated in 3 ways:
- From a JSON file on GitHub
- From an uploaded JSON file
- Manually via the form
Schema validation for each task can be enabled by toggling the Validate Output Schemas button in the task editor.
This enforces that the output schema of a task matches the schema specified and will error if casting is unable to properly resolve the types.
Task Schemas
All Tasks have either an input Schema or an output Schema; many require both. The input Schema defines the structure of data entering a Task while the output Schema defines the structure of data exiting a Task.

A Schema consists of an ordered array of fields.
A field has four elements: name, description, datatype, and nullable.
name refers to the column name being referenced. Note that this value must be unique within a given Schema.
description is meant to provide a space for users to add any useful documentation about the field.
datatype values must be selected from the following list of supported options:
| Datatype | Description |
|---|---|
| BINARY | Binary values |
| BOOLEAN | True or false values |
| BYTE | Byte values |
| DATE | Dates without time values |
| DOUBLE | Double precision values |
| FLOAT | Floating point values |
| INTEGER | Integer values |
| LONG | 32-bit signed integer values |
| SHORT | 16-bit signed integer values |
| STRING | Text or varchar values |
| TIMESTAMP | Dates with time(zone) values |
In general, Kaspian is compatible with any datatype supported by Apache Spark and maps types from Datastores to this list the same way a Spark engine would.
The nullable flag is a boolean option that specifies if the value for that specific field is allowed to be null.
This option can serve as a valuable data integrity check for required fields.
Uploading Schema JSON files
Larger schemas can be provided as JSON files. These files must be in the following format:
[
{
"name": "field1",
"description": "description of field1",
"dataType": "StringType",
"nullable": true
},
{
"name": "field2",
"description": "description of field2",
"dataType": "IntegerType",
"nullable": false
}
]
The dataType naming is based on the Spark data types.
Datastore Schemas
Tables registered in flat file/data lake environments such as AWS S3 can be added as Datastores. This abstraction allows these resources to behave identically to SQL Datastores such as Snowflake and Postgres within the Kaspian compute layer. Kaspian requires that these Datastores have a Schema attached so that data integrity can be programmatically enforced. It is recommended that Datastore Schemas have global scope so that they can be reused by other Pipelines.