Deployment
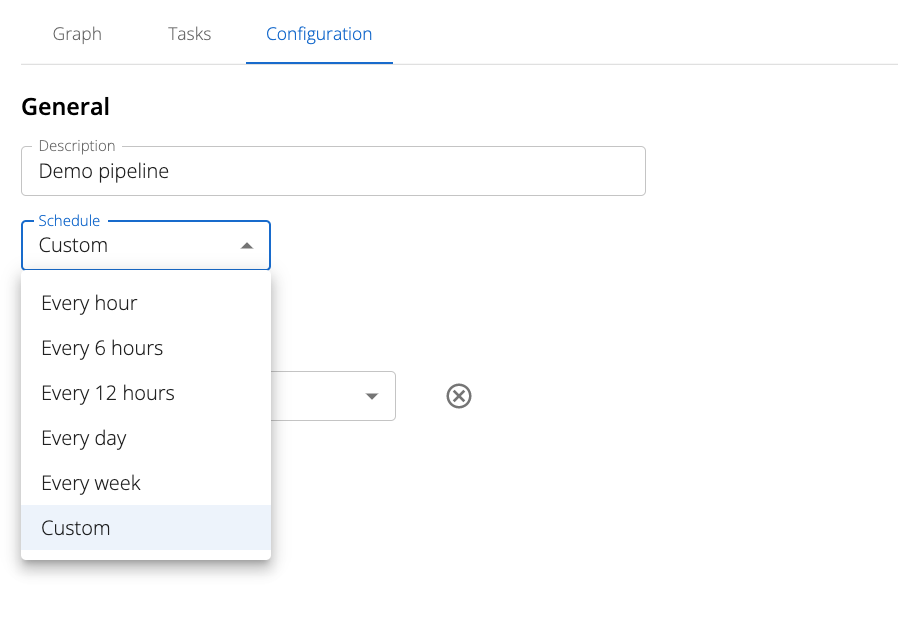
Setting a Schedule
Schedules can be configured via a number of pre-defined intervals or a custom one defined by a user-provided 5-character cron string. This is compatible with the standard cron spec and can be generated via cron string calculators available online.
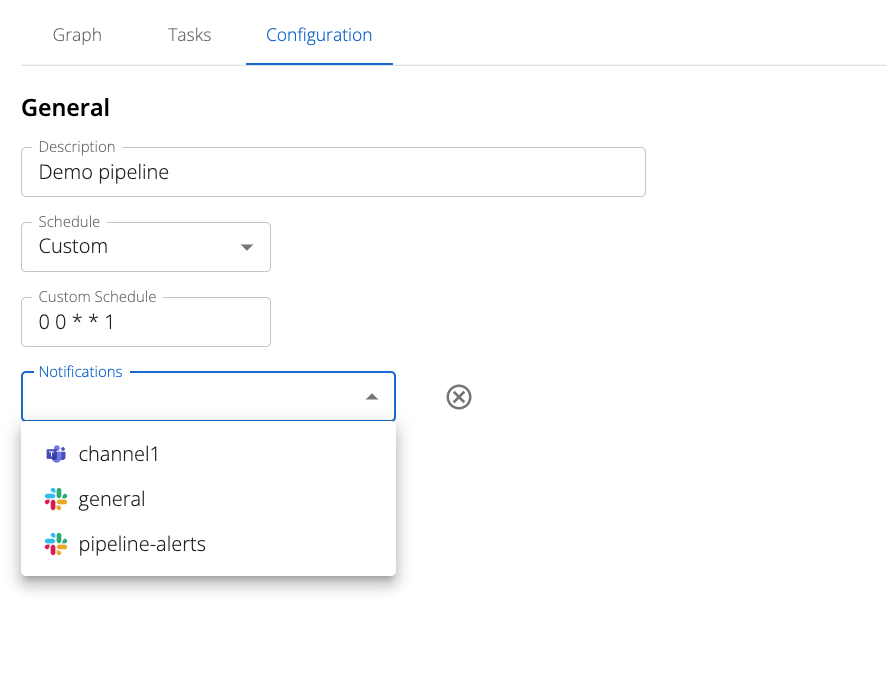
Configuring Notifications
Notifications can be configured to trigger on any pipeline execution failure.
Kaspian offers support for Slack, MS Teams, email, and text notifications. These can be selected via the Notifications dropdown.
Pipeline Actions
There are 2 main modes for a pipeline: an Activated state and a Deactivated state. When a pipeline is activated, it will run at the specified schedule. When a pipeline is inactive, it will not run. When activating a pipeline, a pop-up appears to select a specific pipeline snapshot. Only pipeline snapshots can be activated, so one must be created first.
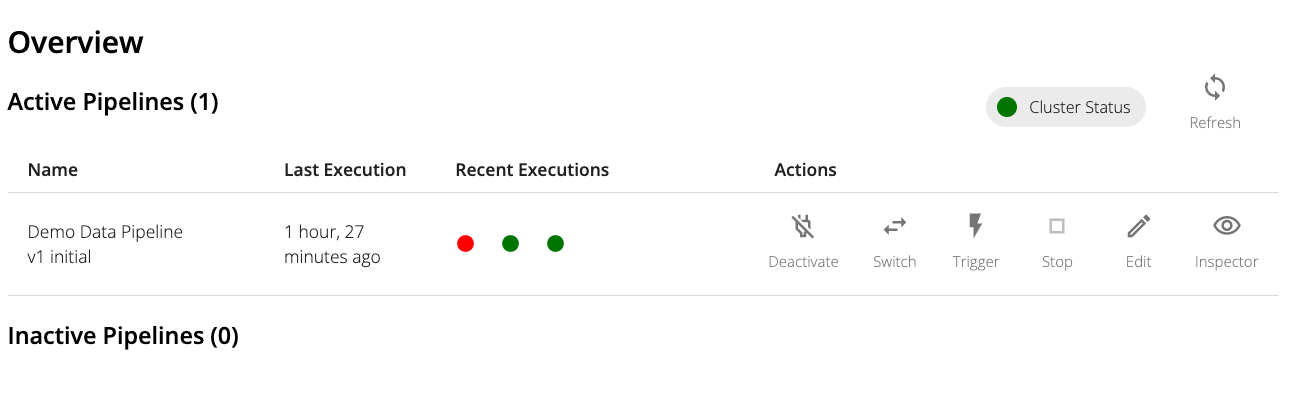
In the activated state, a pipeline can be started ad-hoc at any point in time. In addition, a currently-running pipeline can be stopped at any time.
Previous pipeline executions are depicted as a series of colored dots within the same row as each active Pipeline. The colors correspond to the following statuses:
- Blue: currently executing
- Red: failed
- Green: succeeded
- Gray: canceled
Each dot can be clicked to visit the Inspector view of that specific execution.
Configuring Execution (Beta)
For tuning compute resources for pipeline executions or passing additional configuration options to specific pipeline tasks, Kaspian allows setting Spark parameters at the task level within the Pipeline Builder.
Since only pipeline snapshots can be executed, execution can only be configured for snapshots in the Pipeline Builder. To configure a task, navigate to a specific version of a pipeline within the Pipeline Builder, and click on a task. Then press the “Configure” button in the graph toolbar.
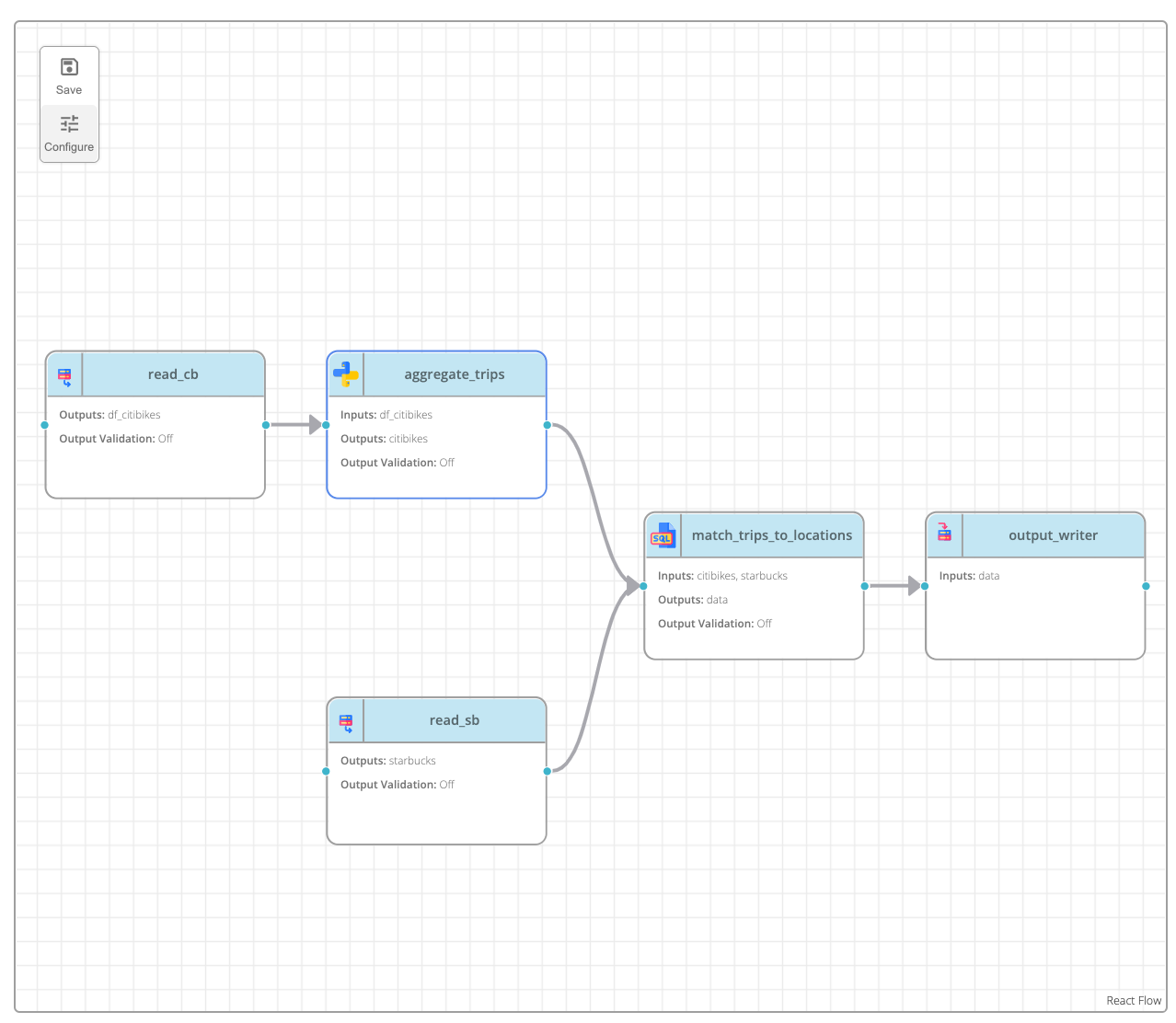
Clicking on the “Configure” button reveals the following form:
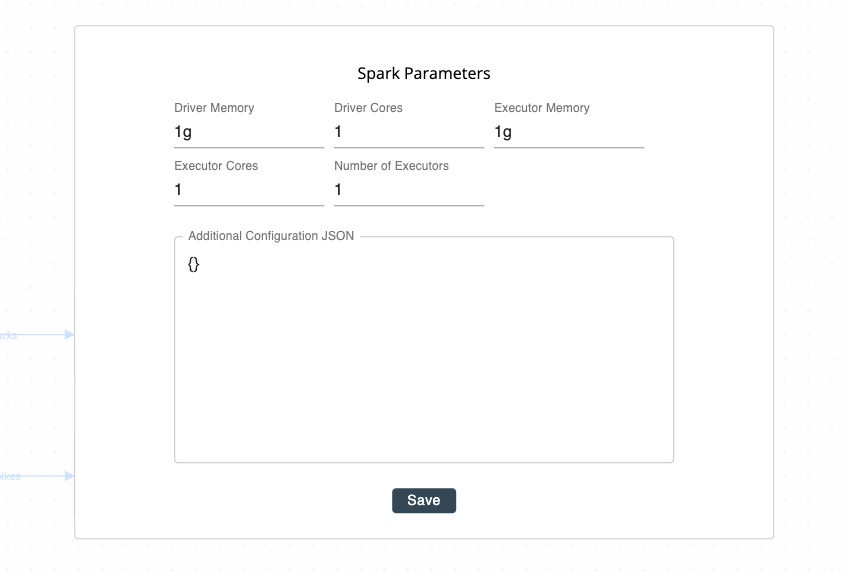
Click “Save” to persist these settings for all future executions of the pipeline snapshot task, or click outside the form to cancel.
Spark Parameters
- Driver Memory: RAM allocated to the Spark driver (default:
1g, or 1 gigabyte) - Driver Cores: Number of cores allocated for the Spark driver (default:
1core) - Executor Memory: RAM allocated to each Spark executor (default:
1g, or 1 gigabyte) - Executor Cores: Number of cores allocated for each Spark executor (default:
1core) - Number of Executors: Number of Spark executors allocated for the task (default:
1executor)
Additional Configuration JSON (Advanced)
For more involved task execution customization, use the “Additional Configuration” section to pass in Spark configuration parameters as a JSON object.